從圖靈測試到深度學習 人工智能發展簡史與基礎軟件開發演進
人工智能(AI)的發展歷程如同一部交織著哲學思辨、理論突破與技術實踐的壯闊史詩,而其基礎軟件的演進則是推動這場智能革命的核心引擎。本文將系統梳理人工智能的發展脈絡,并深入解析支撐AI技術落地的基礎軟件開發歷程與關鍵框架。
一、人工智能發展簡史:三大浪潮與兩次寒冬
人工智能的概念萌芽于20世紀中葉。1950年,艾倫·圖靈在其論文《計算機器與智能》中提出了著名的“圖靈測試”,為人工智能設立了第一個可操作的哲學與工程目標。1956年的達特茅斯會議正式確立了“人工智能”這一學科領域,與會學者樂觀地預言,機器模擬人類所有智能行為的問題將在短時間內取得突破。
第一次浪潮(1950s-1970s):符號主義的黃金時代
早期AI研究集中于“符號主義”或“邏輯主義”路徑,即認為智能源于對符號的物理操作。研究人員開發了能夠證明幾何定理、解決代數問題的程序(如邏輯理論家、通用問題求解器),并誕生了最早的專家系統雛形。由于計算能力的局限和對復雜現實世界建模的困難,AI在70年代遭遇了第一次“寒冬”,資助大幅縮減。
第二次浪潮(1980s-1990s):專家系統與反向傳播算法
80年代,基于規則的知識庫系統(專家系統)在商業領域(如醫療診斷、信用評估)取得成功,掀起了AI的第二次熱潮。連接主義開始復興。1986年,反向傳播算法的重新發現與應用,使得多層神經網絡得以有效訓練,為后來的深度學習奠定了基礎。但專家系統維護成本高昂、難以擴展,神經網絡則受限于數據和算力,導致AI在90年代再次進入調整期。
第三次浪潮(2000s至今):數據驅動與深度學習的崛起
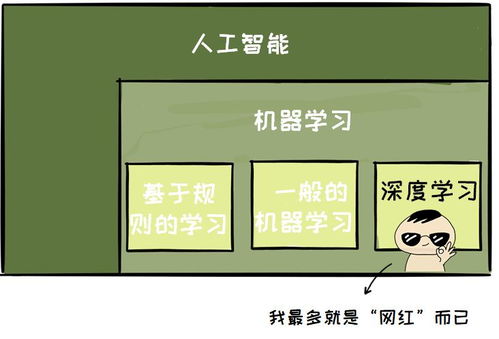
進入21世紀,互聯網催生了海量數據,GPU等硬件提供了強大算力,算法理論(尤其是深度學習)持續突破。2012年,AlexNet在ImageNet圖像識別競賽中以壓倒性優勢獲勝,標志著深度學習時代的開啟。AI在計算機視覺、自然語言處理、語音識別、游戲博弈(如AlphaGo)等領域取得超越人類的性能,并迅速滲透到各行各業。當前,以大模型(如GPT系列)為代表的生成式AI正推動技術邁向通用人工智能(AGI)的新探索。
二、人工智能基礎軟件開發的演進之路
AI基礎軟件是算法、數據和算力之間的粘合劑,其發展緊隨AI研究的步伐,經歷了從專用工具庫到開源生態,再到一體化平臺的演進。
1. 早期探索與專用庫(1990s-2000s)
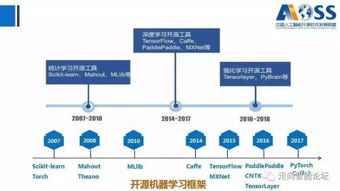
在深度學習興起之前,機器學習軟件多以獨立的、針對特定算法的庫形式存在,如用于支持向量機(SVM)的LIBSVM、用于機器學習的Weka(Java庫)和Scikit-learn(Python庫,2010年發布)。這些庫提供了經典的機器學習算法實現,降低了應用門檻,但尚未形成統一的深度學習框架。
2. 深度學習框架的“戰國時代”與開源化(2010s中期)
隨著深度學習爆發,各大科技公司競相推出核心框架,構建生態。
- Caffe(2013):由伯克利視覺與學習中心開發,專注于計算機視覺,憑借模型定義簡潔和速度快早期流行。
- Theano(2007年啟動,2010s流行):蒙特利爾大學開發,是最早的符號式張量計算框架之一,啟發了后來許多框架的設計。
- Torch(2002年啟動)及其后繼者PyTorch(2016):Torch基于Lua語言。Facebook于2016年推出其Python版本PyTorch,憑借動態計算圖(易于調試、更符合Python編程習慣)和強大的靈活性,迅速成為學術研究的主流選擇。
- TensorFlow(2015):由Google Brain團隊開發并開源。其靜態計算圖設計適合大規模生產部署,憑借Google的強大背書和完整的工具鏈(如TensorBoard可視化、TensorFlow Serving部署),迅速占領工業界市場。
- 其他框架:如微軟的CNTK、百度的PaddlePaddle等,也在特定領域和區域市場占有一席之地。
這一階段的核心競爭在于 “靈活性”(便于研究)與“生產就緒性”(便于部署) 的權衡。
3. 融合、高階API與生態整合(2010s末至今)
為降低開發難度,框架開始提供更高級別的API。
- Keras(2015):最初作為獨立的高級神經網絡API,可以后端調用Theano、TensorFlow等。其“用戶友好、模塊化、易擴展”的設計哲學大受歡迎,后于2017年被正式集成到TensorFlow中,成為其官方高階API。
- PyTorch Lightning、Fast.ai 等庫在PyTorch基礎上進一步封裝,提升研發效率。
兩大主流框架 PyTorch和TensorFlow呈現融合趨勢:PyTorch通過TorchScript、TorchServe等增強生產部署能力;TensorFlow 2.0(2019)則默認啟用動態圖(Eager Execution)并全面擁抱Keras,大幅提升易用性。
4. 大模型時代的基礎軟件新范式
以Transformer架構為核心的大模型訓練,對基礎軟件提出了新要求:極大規模分布式訓練、超長序列處理、萬億參數模型的高效存儲與調度。這催生了新的軟件層:
- 計算圖編譯與優化:如PyTorch的TorchDynamo/AOTAutograd、TensorFlow的XLA(加速線性代數),以及獨立編譯器如TVM、Apache MLIR,旨在提升計算效率。
- 大規模訓練框架:如NVIDIA的Megatron-LM、微軟的DeepSpeed(集成于PyTorch)、Meta的FairScale等,專門解決了大模型訓練中的并行策略、內存優化(如ZeRO優化器)和穩定性問題。
- 一體化平臺:如Hugging Face的Transformers庫,集成了數千個預訓練模型,提供了統一的API,極大地降低了NLP等領域大模型的使用和微調門檻,成為AI開源社區的核心樞紐。
三、與展望
人工智能的發展史,是從人類對自身智能的模仿夢想,走向由數據和算力驅動的工程實踐的歷史。而AI基礎軟件開發史,則是一部將復雜算法抽象化、民主化、工程化的歷史。從早期的數學庫,到深度學習框架的雙雄爭霸,再到大模型時代面向超大規模計算的專用工具鏈,基礎軟件始終是AI能力釋放的關鍵。
AI基礎軟件將朝著 “統一化”、“自動化”和“專業化” 三個方向演進:框架之間的界限可能進一步模糊;AutoML等技術將更深地嵌入開發流程;針對科學計算、機器人、生物計算等垂直領域的專用AI軟件棧將蓬勃發展。軟件,作為智能的載體,將繼續定義人工智能能力的邊界與落地的速度。
最新產品