周易 x3 NPU 精準破解端側AI大模型運行難題,引領人工智能基礎軟件新變革

隨著人工智能技術飛速發展,以GPT、Llama等為代表的大模型展現出驚人的能力。如何讓這些參數量龐大、計算需求驚人的模型在手機、IoT設備、汽車、AR/VR等資源受限的“端側”設備上高效、流暢地運行,已成為行業公認的核心挑戰。計算能效、內存帶寬、功耗控制、模型適配等一系列難題,嚴重制約了端側AI應用的普及與深度。在此背景下,專注于人工智能基礎軟件與硬件協同設計的創新力量,如“周易”系列,其最新一代NPU(神經網絡處理器)架構——周易 x3 NPU,正通過精準的系統級優化,為端側大模型運行提供了關鍵的解決方案,驅動著人工智能基礎軟件的深刻變革。
一、 端側大模型運行的“阿喀琉斯之踵”:核心難題剖析
在將大模型部署至端側時,開發者主要面臨三大核心瓶頸:
- 算力與能效的極致矛盾:大模型推理需要海量計算,而端側設備的計算資源(特別是傳統CPU/GPU)有限,且必須嚴格遵循功耗與散熱預算。粗暴的算力堆疊在端側既不現實也不經濟,如何實現單位功耗下的極致算力(即高能效比)是首要課題。
- 內存墻與帶寬限制:大模型的參數動輒數十億甚至上百億,遠超端側設備有限的片上存儲。頻繁從外部內存(如DDR)讀取權重和中間結果,會帶來巨大的延遲和功耗,形成“內存墻”,嚴重拖慢推理速度。
- 軟件棧的適配與優化鴻溝:即使有了專用硬件,也需要與之深度匹配的軟件棧(編譯器、運行時庫、算子庫、模型壓縮工具鏈等)將主流AI框架(如PyTorch, TensorFlow)下的大模型高效“翻譯”并部署到硬件上。軟件棧的效率直接決定了硬件性能的發揮程度。
二、 周易 x3 NPU:以精準架構設計直擊痛點
“周易 x3 NPU”并非簡單的算力提升,而是圍繞上述難題進行了一系列精準的架構與系統級創新:
- 異構計算與任務智能調度:x3 NPU內部采用多核異構或可重構計算單元設計,能夠智能識別大模型中不同類型的計算任務(如矩陣乘、卷積、注意力機制中的softmax等),并將其分派到最擅長的計算單元上執行,避免資源閑置與浪費,最大化計算效率。
- 創新的內存子系統與數據復用:針對“內存墻”,x3 NPU通過設計大容量、高帶寬的片上緩存(SRAM),并采用智能的數據切片、權重壓縮(如INT4/INT8量化)和緩存策略,極大減少了對外部內存的訪問頻次和數量。其數據流架構優化了計算過程中的數據復用,進一步降低了帶寬需求。
- 稀疏計算與動態精度支持:大模型普遍存在權重和激活值的稀疏性。x3 NPU硬件原生支持稀疏計算,能夠跳過零值計算,直接提升有效算力。支持混合精度推理(如FP16, INT8, INT4),允許在保證精度的前提下,為不同層或算子選擇最經濟的精度,實現精度與性能的最佳平衡。
三、 人工智能基礎軟件的關鍵賦能:軟硬協同的勝利
周易 x3 NPU的強大,一半功勞歸于與之緊密協同的、先進的人工智能基礎軟件棧。這套軟件生態精準地解決了“最后一公里”的部署問題:
- 高性能編譯與優化器:其配套的AI編譯器能夠對來自主流框架的大模型進行深度圖優化、算子融合、內存分配優化等,生成高度優化、針對x3 NPU硬件特性的高效執行代碼,充分挖掘硬件潛力。
- 全棧模型部署與工具鏈:提供從模型量化、剪枝、知識蒸餾等壓縮工具,到輕量化運行時引擎的一站式工具鏈。開發者可以便捷地將龐大的原始模型轉化為適合端側部署的“瘦身”版本,并通過運行時引擎進行高效、低延遲的推理。
- 開放與易用的生態接口:良好的軟件棧會提供標準的API(如ONNX Runtime兼容接口、TFLite Delegate等),讓開發者能夠以較低的學習成本,將現有AI應用遷移到x3 NPU平臺上,加速了創新應用的落地。
四、 應用前景與行業影響
周易 x3 NPU及其基礎軟件棧的成熟,正打開端側智能的想象空間:
- 智能手機:實現更實時、更私密的端側大語言模型對話、圖像生成、視頻實時增強等應用,且無需依賴云端,保護用戶隱私。
- 智能汽車:支撐艙內更復雜的多模態交互(語音、視覺)、自動駕駛感知模型的實時推理,提升安全性與響應速度。
- AIoT與邊緣計算:讓攝像頭、機器人等設備具備更強的本地實時分析和決策能力,減少對云端的依賴和網絡延遲。
- AR/VR設備:實現低延遲的視覺SLAM、手勢識別與虛擬物體交互,提升沉浸體驗。
###
端側AI大模型的普及浪潮已至,其成功的關鍵在于硬件算力與基礎軟件的高度協同與精準優化。以周易 x3 NPU為代表的解決方案,通過從芯片架構到軟件工具鏈的全棧創新,精準命中了端側部署在能效、內存和易用性上的核心痛點。這不僅是單一技術的突破,更是對人工智能基礎軟件開發范式的一次重要引領——它標志著AI計算正從粗放式的云端集中處理,走向精細化的、軟硬一體的全域智能時代。隨著類似技術的不斷迭代與生態完善,每一個終端設備都將可能擁有媲美云端的智能,真正實現人工智能的無處不在。
最新產品
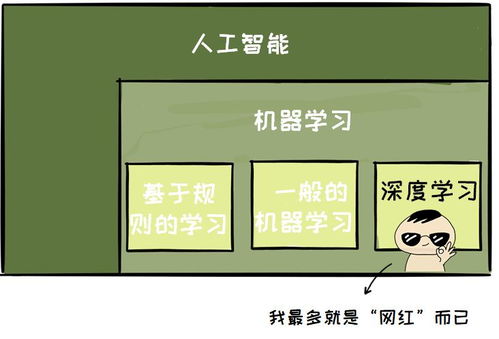
人工智能入門指南 邁出扎實第一步,避開基礎軟件開發“坑”

2021-2025年中國人工智能基礎數據服務與軟件開發行業市場開發與拓展戰略研究報告
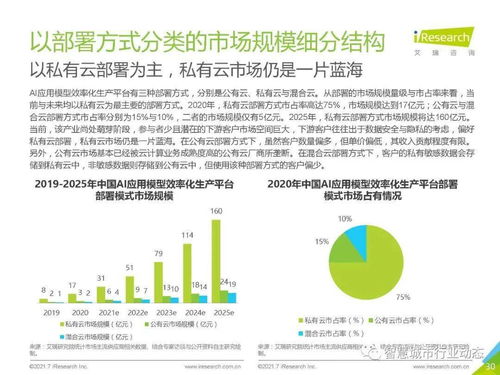
2021年中國人工智能基礎層行業報告 基礎軟件開發現狀、挑戰與未來趨勢

韓媒警示 美國在人工智能基礎軟件領域壟斷加劇,全球技術格局面臨重塑
中電信人工智能科技公司增資至約33.7億元,AI基礎軟件開發布局深化
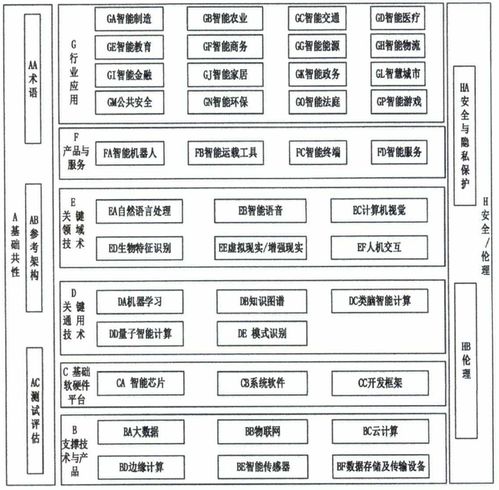
《國家新一代人工智能標準體系建設指南》發布,人工智能基礎軟件開發迎來標準化新機遇
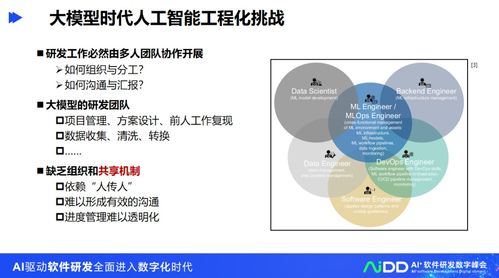
清華大學龍明盛 引領人工智能工程化與基礎軟件創新的先鋒
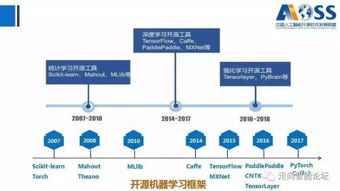
2018中國人工智能開源軟件發展白皮書 聚焦人工智能基礎軟件開發的機遇與挑戰
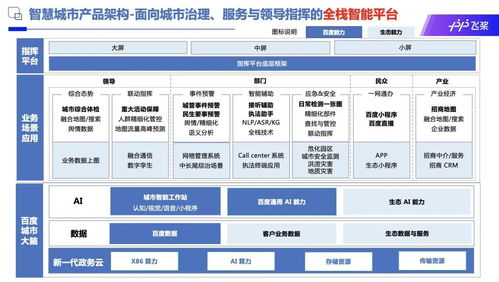
數字新基建下的AI引擎 人工智能基礎軟件如何賦能智慧城市
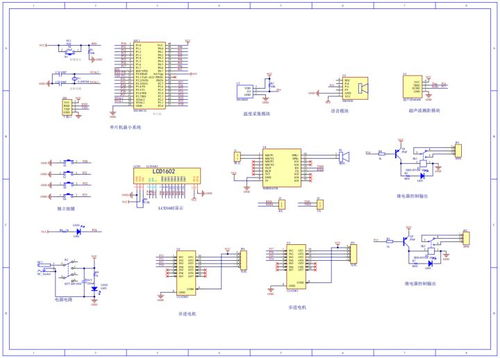
智能家居聯動控制 基于人工智能基礎軟件的開發與創新